

UABC Algoritmos
Introducción
Sílabo
Se provee una primera etapa de abstracción y razonamiento lógico matemático para identificar las limitaciones de los modelos actuales de computación. Esto se enmarca en el área de la teoría de la computación, la cual se encarga de establecer los fundamentos de las ciencias computacionales de manera formal y realizar un análisis lógico-matemático de las soluciones algorítmicas propuestas para diferentes problemáticas, así como de proponer soluciones alternativas utilizando técnicas avanzadas de diseño de algoritmos.
Programa de unidad de aprendizaje.
Prefacio
Curso impartido en la UABC. Revisado por el Dr. Everardo Gutiérrez López y escrito por su alumno Carlos Eduardo Sánchez Torres.
Este texto y sus recursos se rigen bajo la licencia CC BY-NC-SA 4.0.
Si estas viendo estas notas como PDF u otros formatos, puedes encontrar una versión web en:
https://sanchezcarlosjr.com/UABC Algoritmos 38fac5ca34e740719b43673db9f8b918
Una versión en inglés y más actualizada:
Recursos
Fundamentales
Complementarias
| Name | Tags |
|---|---|
| https://www.cl.cam.ac.uk/teaching/1819/Algorithms/2018-2019-stajano-algs-handout.pdf | |
| Untitled | |
| Untitled |
Ecosistema
Esta curso se contexualiza en Ciencias Computacionales:
- Computación
- Teoria de la computación
- Análisis y diseño de Algoritmos
- Teoria de la computación
ACM Computing Classification System
Curso fundamental para ¿Qué es lo que sigue? ¿Cuál es el estado del arte?
Si te interesan los retos y las matemáticas:
Si te interesa el open source:
Ambos eventos abren convocatoria a inicio de año y debes pasar por una serie de filtros.
- Google Summer of Code. -te pagan por contribuir y ganas experiencia-.
Si te interesa participar en programación competitiva -nivel universitario-:
- ICPC México: https://blogs.iteso.mx/acm/
- Sitio para practicar gratis: https://codeforces.com/
- Plataforma mexicana: https://omegaup.com/ (ayuda a estudiantes a participar en la OMI).
- Algoritmos y estructuras: https://cp-algorithms.com/
¿Qué opina el profesor Cormen de la programación competitiva?
Si te interesa trabajar en una gran empresa como las FANG o en casas de videojuegos AAA, es seguro que te aplicarán entrevistas técnicas -en inglés-.
Sitio para practicar gratis: https://leetcode.com/, https://www.hackerearth.com/
Investigación
Si te interesa la investigación:
Historia
Recomendaciones para aprender y métodos de aprendizaje
- Programe los ejercicios en su lenguaje de programación favorito. Se recomienda Python.
- Intente resolver más ejercicios que los propuestos.
Preguntas frecuentes
¿Por qué estudiar algoritmos?
Ley de
Wirth, en su artículo de 1995 A Plea for Lean Software, él se la atribuye a Martin Reiser.
Los algoritmos son el centro de estudio de las ciencias computacionales: la algoritmia o algorítmica es la piedra angular de esta ciencia -que lo es-. Este curso tiene como propósito que tú analices algoritmos para su determinar su eficiencia, y técnicas para crearlos.
Como sabrás de tus clases de ingeniería de software, en los sistemas grandes se suele dar preferencia a:
- Modularidad,
- Corrección,
- Mantenibilidad,
- Seguridad,
- Funcionalidad,
- Tiempo de desarrollo,
- Simplicidad,
- Experiencia de usuario,
- Extensibilidad,
- Escalabilidad,
- Facilidad de leer
Entonces, ¿por qué es importante estudiar algoritmos y su rendimiento?
- El rendimiento marca la línea entre un problema factible y el que no: los seres humanos no vivimos miles de años para que un algoritmo termine.
- Algoritmos dan el lenguaje para hablar sobre el comportamiento, y no sobre cuestiones sintácticas de un lenguaje de programación. El objetivo es medir la calidad de los algoritmo por su complejidad en tiempo y espacio.
- Formalizamos algoritmos, consiguiendo crear técnicas para resolver problemas complejos: Ray Tracing, transformada de Fourier discreta, algoritmos multihilo, programación lineal, ...
Conceptos clave
| Concepto | Def. | Características | Ejemplos y tipos |
| Problema computacional o problema. Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein. Introduction to Algorithms. The MIT Press, 4ª Ed., 2022 | Una pregunta general a ser respondida. | Un problema es descrito por: Conjunto Instancia, entrada. Discurso de dominio descrito por parámetros o variables independentes. Una instancia del problema son valores específicos para estas variables. Solución o salida. Conjunto que satisface el predicado . | Por foma del conjunto. Decisión. Búsqueda. Optimización. Conteo. Por decibilidad. Indecidibles. Decidibles. Por tratabilidad. Tratable o factibles (fácil o problemas P), si y solo si hay algún algoritmo eficiente. Intratable, si y solo si NO hay algún algoritmo eficiente. |
| Algoritmo Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein. Introduction to Algorithms. The MIT Press, 4ª Ed., 2022 | Def. estipulativa Es un procedimiento computacional bien definido paso por paso que para cada entrada da una salida. Herramienta para resolver problemas computacionales. Def. formal Un algoritmo es una máquina de Turing que dada una cadena de entrada eventualmente para. Advertencia: computacional no refiere a que sea un programa o que deba ser escrito en un lenguaje de programación. Recuerda: niveles de abstración. | Finito. El algoritmo termina, esto es, puede finalizar en una cantidad finita de tiempo. Definido (preciso). Libre de ambigüedad. Entrada. Recibe un conjunto entrada que , precondición. Salida. Da un conjunto salida que , postcondición. General. El algoritmo funciona para cualquier instancia del problema. Para este curso, aunque no exclusivamente, Determinista. Se espera que sea Correcto. Que el conjunto salida es igual al conjunto solución. Legible. Simple de leer y autocontenido. | Por tiempo de ejecución. Tiempo polinomial. . Tiempo exponencial. . Por eficiencia. Eficiente. Si . Ineficiente. En otro caso. Por aleatoriedad. Aleatorios. Deterministas. Por cantidad de procesadores. Secuenciales. Multihilo. |
| Programa Knuth, D. E. (1997). The art of computer programming (3rd ed.). Addison Wesley. | Expresiones de un método computacional en un lenguaje de programación es llamado programa. | ||
| Método computacional/Procedimiento Knuth, D. E. (1997). The art of computer programming (3rd ed.). Addison Wesley. | Es un procedimiento computacional bien definido paso por paso que dada una entrada da una salida que puede NO terminar. Advertencia: NO confundir con los métodos de OOP. |
Ejemplos
| Problema computacional | Algoritmos |
| Ordenamiento. Entrada. Sequencia de números . Salida. Una permutación de la sequencia de entrada tal que . | QuickSort BubleSort MergeSort ... |
| Fibonacci. Entrada. . Salida. tal que , | Fibonacci recursivo. Fibonacci iterativo. Fibonacci en forma cerrada. |
Latex y pseudocódigo
Tú también puedes crear algoritmos que se vean como Introduction to algorithms: https://mitp-content-server.mit.edu/books/content/sectbyfn/books_pres_0/11599/clrscode4e.pdf
Herramientas de Análisis de Algoritmos
El análisis de un algoritmo es el proceso de encontrar el tiempo y espacio necesario para ejecutarlo, abstrayendo la velocidad de ejecución de la máquina real, midiéndolo en función del tamaño y forma de la entrada.
Eficiencia (o complejidad) en tiempo y espacio
La función que mide el tiempo de ejecución de un algoritmo es , que relaciona el número de pasos -operaciones básicas- con el tamaño de la entrada. Por otra parte mide el espacio dependiendo del tamaño de la entrada. Asumimos que trabajamos en una RAM (máquina de acceso aleatorio, la cual opera igual que una real) y que sus operaciones básicas operaciones son constantes (para mayor informacion vease un curso de arquitectura de computadoras), esto es, que no varían por el tipo ni por el tamaño de la entrada:
- Operaciones aritméticas (sumar, restar, multiplicar, dividir, resto, piso).
- Operaciones lógicas.
- Movimiento de datos (carga, copia, guardar): asignaciones.
- Control (llamadas a subrutinas, condicionales, ...).
El procedimiento para encontrar : contar el número de operaciones simples en función del tamaño de entrada (recurrencias, analizado amortizado, conteo, ...), luego pensar en cuales son las condiciones para que el algoritmo ejecuta la mayor, la menor y el promedio de ejecución y por último, encontrar su orden de crecimiento, esto es, su eficiencia asintótica.
El procedimiento para encontrar : contar el número de unidades de memoria consumidas.
Para esto es crucial que aprendas Finite Calculus.
Análisis empírico de la eficiencia de un algoritmo: «profiling» y «benchmarking»
Existen maneras empíricas o experimentales para lucidar la eficiencia de un algoritmo, sin embargo, estas no son formales, esto significa que sus resultados no son generalizables: son dependientes de la máquina, del lenguaje de programación, … Por tanto, no son objeto de estudio de este curso. Esto implica, que los ejercicios se esperan sean resueltos analíticamente: libres de un lenguaje de programación y computadoras concretas, ...
Recuerda: programar en tu lenguaje favorito y ejecutarlo para un finito casos de prueba no es una demostración.
Algunas herramientas CASE para «profiling» y «benchmarking»:
Tipos de tiempos de ejecución de los algoritmos
| Peor caso de ejecución | Caso promedio de ejecución | Mejor caso de ejecución | Esperado tiempo de ejecución |
| El caso donde el algoritmo ejecuta la mayor cantidad de pasos o el máximo tiempo necesario dada una entrada pésima sobre todas las entradas de tamaño , esto es, que la sea las más grande posible: | La cantidad promedio de pasos o el promedio de tiempo necesario para ejecutar el algoritmo dada sobre todas las entradas de tamaño . Entonces, buscamos la entrada promedio o típica mediante análisis probabilístico, es decir, la distribución de probabilidad sobre los datos de entrada: Advertencia: * No es el promedio del peor caso y el mejor caso. | El caso donde el algoritmo ejecuta la menor cantidad de pasos o el menor tiempo necesario dada una entrada óptima de tamaño , esto es, que la T(n) sea la menor posible: | Cuando el algoritmo es aleatorio caracterizamos con el tiempo esperado: , donde t es el posible tiempo para el algoritmo y la probabilidad Pr(t) de que ese tiempo ocurra. Advertencia: no confundir con el caso promedio de ejecución. |
En el curso, buscamos el peor caso porque aunque el caso promedio es el típico, por la Ley de Morphy sabemos que el peor caso es siempre posible.
Caso promedio
Variables aleatorias. Es una función, X: S → N
Variables aleatorias indicadoras Es una función X: S → {1,0}
Esperanza matemática (promedio).
Distribucion uniforme. elementos,
Ejemplos trabajados
Ejemplo 1 de T(n)
c=1+1; c1Ejemplo 2 de T(n)
b=1; c1
c= 1 if 1==b else 2; c2Ejemplo 1
S={HH,AA,HA,AH}
X: cantidad de H
X(HH)=2
X(AA)=0
X(HA)=1
X(AH)=1
Ejemplo 2
S={HH,AA,HA,AH}
X: si H aparece 1, si H no aparece 0.
X(HH)=1
X(AA)=0
X(HA)=1
X(AH)=1
Ejemplo 3
S={H,A}
X: si H aparece 1, si H no aparece 0.
X(H)=1
X(A)=0
Ejemplo 4
en el arreglo: [1,2,3].
, ,
Ejemplo 5
...
(el total de Hs en experimentos)
¿Cómo comparamos algoritmos?
Lo anterior significa que nuestro problema de comparar algoritmos se reduce a comparar funciones , tal que si
El algoritmo con es más rápida que el algoritmo con , donde siempre se quiere la función más pequeña -más cercana a 0-, por tener menor tiempo de ejecución.
Ejemplo 1
Si y ¿Cuándo ?
https://www.geogebra.org/calculator/mkk7dpeqhttps://www.geogebra.org/calculator/mkk7dpeq¿En cuáles dos funciones se intersecan o son iguales?
Ejemplo 2
Supón que estamos comparando implementaciones de insertion sort y merge sort en la misma máquina. Para entradas de , insertion sort corre en pasos, mientras que merge sort corre en pasos. ¿Para cuáles valores de , insertion sort supera a merge sort?
Esto implica
Ejemplo 3
¿Cuál es el valor más pequeño tal que un algoritmo cuyo tiempo de rendimiento es es más rápido que un algoritmo de tiempo en la misma máquina?
Ejemplo 4
Determine la más grande que que pueda resolver en 1 segundo, suponiendo toma microsegundos.
Donde , medida en , indica cuántas instrucciones se ejecutan por unidad de tiempo, en el ejemplo,
¿Cómo demostramos que un algoritmo/programa funciona? Program verification and correctness
Manual
Cálculo de predicados, condiciones débiles (precondiciones) y fuertes postcondiciones -Predicate transformer semantics, Hoare logic-
https://raw.githubusercontent.com/fraunhoferfokus/acsl-by-example/master/ACSL-by-Example.pdf
https://allan-blanchard.fr/publis/frama-c-wp-tutorial-en.pdf
Invariante de lazo. Cálculo particular de Hoare Logic para ciclos.
T g() {}
// Si inicie bien -Inicialización. Establecimiento. Precondiciones- y
Q;
// me mantego haciendolo bien -Mantenimiento. Preservación.-
// Invariente I
while(P(Q)) {
// Q --> no P(Q)
}
// cuando terminé -Terminación.-
assert no P(Q) and I;
// estaré bien.
}Ejemplo:
int f() {
// Si inicie bien -Inicialización. Establecimiento. Precondiciones- y
int i = 0;
// me mantego haciendolo bien -Mantenimiento. Preservación.-
//@ loop invariant 0 <= x <= 30
while(i < 30) {
i++;
}
// cuando terminé -Terminación.-
//@ assert i == 30; // por que [no (i < 30) y (0 <= i <= 30)]
// estaré bien.
return i;
}
Automática
Lean Prover.
COQ.
WhyML
FramaC.
https://sanchezcarlosjr.medium.com/state-of-art-in-correctness-made-by-compilers-4b89f964d29
https://www.adacore.com/uploads/technical-papers/2016-10-SPARK-MisraC-FramaC.pdf
Algunos shortcircuits
if (P)
if (Q)
r;es equivalente
if (P && Q)
R;Referencias
Tony Hoare’s paper, “An Axiomatic Basis for Computer Programming”.
https://cacm.acm.org/magazines/2015/4/184701-how-amazon-web-services-uses-formal-methods/fulltext
https://raw.githubusercontent.com/blanchette/logical_verification_2021/main/hitchhikers_guide.pdf
https://www.youtube.com/watch?v=U5i2VQj5jPk&ab_channel=Computerphile
Caso de estudio: suma
Input: Una secuencia de números reales .
Output: Un valor real , tal que
SUM(A)
n = A.length c1(1)
r = A[n] c2(1)
for j = n-1 downto 1 c3(n)
do r = r + A[j] c4(n-1)
return r c5(1)Invariante de lazo. En el inicio de cada iteración del bucle for lineas 3-4, es igual a la suma de los últimos elementos de .
Inicialización.
Al inicio de la primera iteración, y , por lo tanto es igual a la suma de los últimos elementos de , lo cual implica que se cumple la invariante de lazo.
Mantenimiento.
Al inicio de la iteración donde , suponemos cierta la invariante por lo que (la suma de los últimos elementos de ). En la línea , el elemento es sumado a , i.e., al inicio de la siguiente iteración, donde , es decir, la suma de los últimos elementos de , lo cual implica que se cumple la invariante de lazo.
Finalización.
Cuando el bucle termina, , y por la invariante tenemos , es decir que contiene la suma de los y tenemos que últimos elementos de (i.e., la suma de todos los elementos de ).
Por lo tanto, el algoritmo es correcto.
Complejidad temporal.
.
Caso de estudio: búsqueda binaria
Entrada: Una secuencia de n números A = <a1, a2,..., an> y un valor v.
Salida: Un índice i tal que o el valor especial NIL si v no se encuentra en A.
binary_search(A, v):
if A[-1] < v:
return Nil
p = 0
r = len(X)
while p < r:
mid = (p+r)//2
if A[mid] == v:
return mid
if A[mid] < v:
p = mid + 1
if A[mid] > v:
r = mid - 1
return Nil- Utilizando la técnica de invariante de lazo, demuestre que el algoritmo es correcto.
- Calcule el tiempo de ejecución en el mejor y peor caso. Calcule también el total en promedio, suponiendo que el elemento a buscar es cualquiera de los contenidos en el vector con la misma probabilidad. Exprese los casos utilizando notación asintótica.
Notebook
Notas y recursos
Para visualizar alguno de los algoritmos: https://visualgo.net/en o https://algorithm-visualizer.org/
https://tildesites.bowdoin.edu/~ltoma/teaching/cs231/duke_cps130/Lectures/L06.pdf
https://www.cs.stanford.edu/~trevisan/cs254-10/lecture02.pdf
https://web.stanford.edu/class/archive/cs/cs161/cs161.1138/lectures/19/Small19.pdf
Preguntas frecuentes y no tan frecuentes
¿Hay (theta pequeña)?
No. https://stackoverflow.com/questions/25593619/why-doesnt-small-theta-asymtotic-notation-exist
¿Es lo mismo peor caso, mejor caso y caso promedio que el análisis asintótico?
No.
Técnicas de Diseño de Algoritmos
La siguiente lista -no exhaustiva- de técnicas, patrones de diseño, métodos o paradigmas son enfoques para encontrar algoritmos óptimos:
- Métodos Heurísticos.
Divide y vencerás (divide et impera)
Para resolver problemas con Divide y vencerás consiste en los siguientes tres pasos:
- Divide el problema en subproblemas substancialmente más pequeños e independientes.
- Resuelve los subproblemas recursivamente cuando sean grandes (caso recursivo), pero si el tamaño del sub-problema es suficientemente pequeño simplemente resuélvelo (caso base).
- Combina las soluciones de los subproblemas en la solución del problema original.
Análisis
Los algoritmos recursivos deben analizarse de manera distintos a otra clase: usamos recurrencias, porque son una manera natural de medir su tiempo.
Relaciones de recurrencia
Dos maneras de resolver la recurrencia:
- Árbol de recurrencias.
Ecuaciones de recurrencia.
Método maestro: , .
Si entonces
Si para alguna constante y para alguna constante y todas las suficientemente grandes, entonces .
Si para alguna constante , entonces
Sin embargo, como te darás cuenta en los siguientes ejercicios, el método maestro, aunque bastante rápido, es bastante limitado, asi surgio la necesidad de generalizarlo: método Akra–Bazzi (https://link.springer.com/article/10.1023/A:1018373005182.
Una manera de demostrar nuestra suposición:
- Método de sustitución.
Ejemplo 1 con Árbol de recurrencias.
Sum(n) {
if n == 1
return 11
return n + Sum(n-1)
}Solución
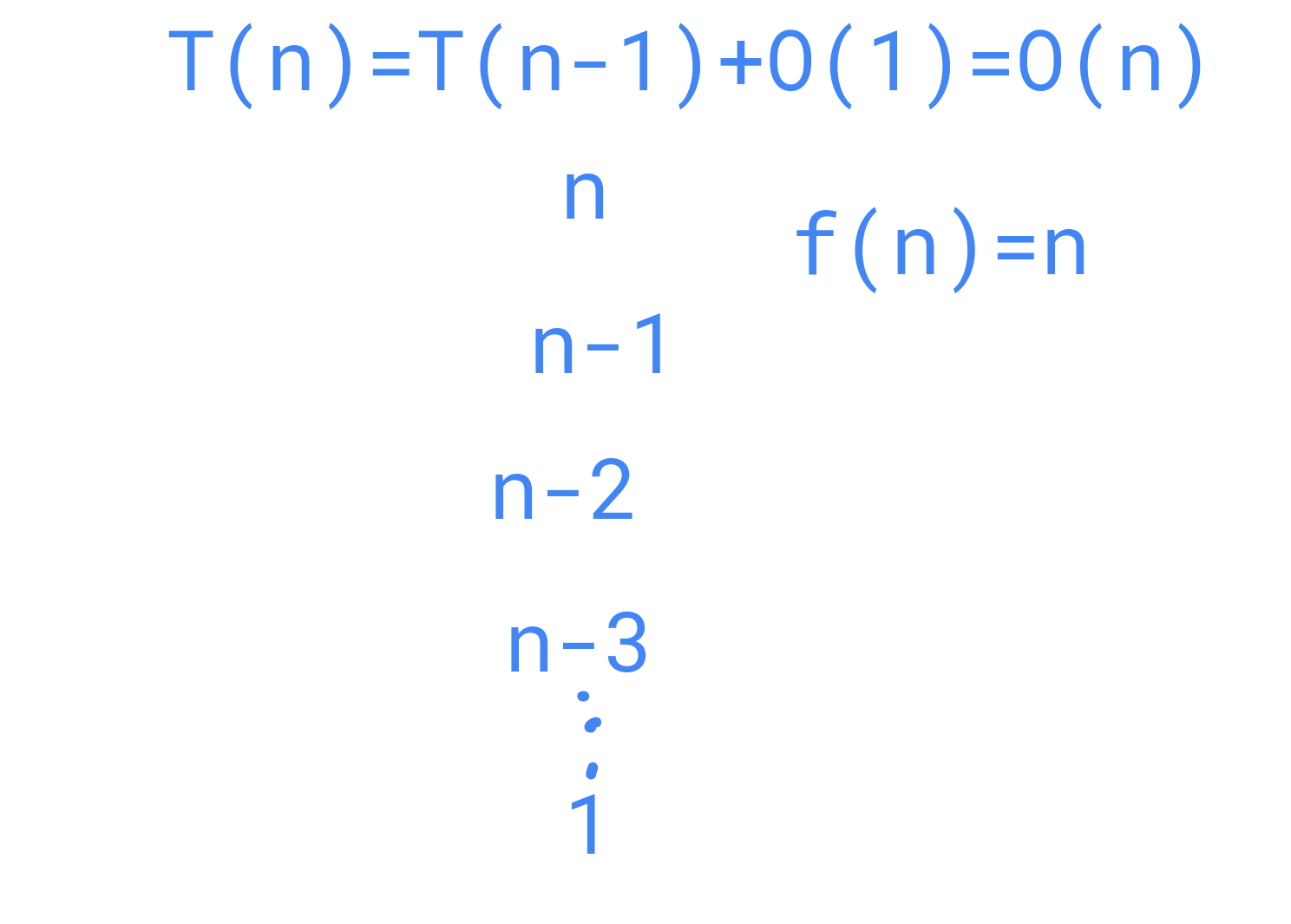
Árbol de recurrencias.
Ejemplo 2 con Método maestro
recursiveFun1(n)
{
if (n <= 0)
return 11;
else
return 11 + recursiveFun1(n/2);
}Solución
1.
, ,
2.
,
Ejemplo 3 con Método maestro
recursiveFun3(n)
{
if n <= 0
return 11
else
return 11 + recursiveFun3(n/5)
}Solución
1.
,
,
2.
,
Entonces
Ejemplo 4
int recursiveFun2(int n)
{
if (n <= 0)
return 11;
else
return 11 + recursiveFun2(n-5);
}Solución
Ejemplo 5
int recursiveFun5(int n)
{
for (i = 0; i < n; i += 2) {
// T(n)=c1+c2+c3+...=c
}
if n <= 0
return 1
else
return 1 + recursiveFun5(n-5)
}Solución
Ejemplo 6
void recursiveFun4(int n, int m, int o)
{
if (n <= 0)
{
printf("%d, %d\n",m, o);
}
else
{
recursiveFun4(n-1, m+1, o);
recursiveFun4(n-1, m, o+1);
}
}Solución
Dado que la cantidad de pasos esta determinada por , entonces:
printfes constante.
- Buscamos
Así
Ejemplo 7 Factorial
factorial(n)
{
if (n == 0)
{
return 1
}
return n * factorial(n-1);
}Solución
...
Caso de estudio: Permutación
Encuentra , para cualquier algoritmo de permutación y elimina la recursión.
string permute(string str, int index = 0, string acc = "") {
if (index == str.length() - 1) {
acc += str + "\n";
return acc;
}
for (int subIndex = index; subIndex < str.length(); subIndex++) {
swap(str[index], str[subIndex]);
acc = permute(str, index + 1, acc);
}
return acc;
}Solución
permute(elements): x = elements y = [] n = len(x)-1 while n > 0: for i in range(0, len(x), n+1): for j in range(i, i+n+1): for k in range(i, i+n+1): if j != k: y.append(x[j]+x[k][-1]) n = n-1 x = y y = [] return x
Caso de estudio: Máximo común divisor
Encuentra y elimina la recursión.
gcd(int a, int b)
if b == 0
return a
return gcd(b, a mod b)Solución
gcd(int a,int b) while b != 0 a,b = b, a mod b return a
Los problemas, mas no las soluciones, fueron obtenidos en
Programación dinámica (PD)
Creada por Richard Bellman en la RAND corporation, programación es, por inglés británico, optimización. Proviene de programación lineal -método tabular- y no refiere a escribir código. El nombre puede ser un poco oscuro, y eso es por cuestiones políticas: el nombre fue eligido para convencer a sus jefes ocultando el hecho de que estaban investigando matemáticas, programación porque estaba de moda y dinámico para que el nombre suene más interesante. El nombre original era: optimally plan multistage processes.
Esta técnica es parecida a divide y vencerás, donde en aquel vimos subproblemas independientes y pequeños () resueltos recursivamente, en programación dinámica los subproblemas son dependientes, no tan pequeños (), resueltos iterativamente, y regularmente usado para problemas de optimización (lo cual implica tomar decisiones dirigida a encontrar la mejor solución). En general, convierte algoritmos con tiempo exponencial a tiempo polinomial.
Este paradigma resuelve cada subsubproblema y entonces lo guarda en una tabla, evitando el recálculo cuando los siguientes subproblemas necesiten la respuesta a ese subsubproblema, a esto se le conoce como memoización (no memorizar, memoizar), que es la idea central de PD, que en otras palabras, memoizar significa recordar y reusar soluciones de subproblemas.
Pasos para usar este paradigma:
- Caracterizar la estructura de una solución óptima.
- Definir recursivamente el valor de una solución óptima.
- Calcular el valor de una solución óptima en un esquema bottom-up (iterativo) o top-down (recursivo).
- Construir una solución óptima a partir de la información calculada.
O también puedes el marco de trabajo SRBOT:
1. Definir subproblema con palabras.
- Escribir el subproblema en términos del valor de la solución o de la solución en sí misma -a veces pueden coincidir, pero no son lo mismo-: no es lo mismo el tamaño de la secuencia que la secuencia.
2. Relacionar las soluciones de los subproblema recursivamente.
- Muchos de las relaciones involucran el uso las funciones .
- Es el paso más difícil.
3. Orden topológico de los subproblemas (en este caso, es un subproblema DAG).
4. Caso base de la relación.
5. Original problema vía subproblemas.
- Si la relación de recurrencia es lineal, el problema puede ser resuelto en , véase ecuaciones en diferencias.
- En otro caso, debe ser un esquema bottom-up (iterativo) o top-down (recursivo).
6. Tiempo de análisis.
Notas y referencias
MIT 6.006 Introduction to Algorithms, Spring 2020
MIT 6.006 Introduction to Algorithms, Fall 2011
Estrategias voraces, ávidas o glotonas (Greedy algorithms)
Al igual que la programación dinámica, los algoritmos voraces buscan una solución con el óptimo resultado, en el primero para algunos problemas determinar la mejor solución global dado el conjunto de pasos en cada paso puede ser muy costoso, en el segundo buscamos la mejor solución en el momento, esto significa, seleccionar soluciones óptimas locales repetidamente con esperanza de que esa sea la solución global, claramente, esto no significa que no siempre dará la solución óptima global.
Pasos para usar este paradigma:
- Caracterizar la subestructura óptima del problema.
- Desarrollar una solución recursiva.
- Mostrar que la elección es voraz, entonces un subproblema pertenece.
- Demostrar que es una elección segura.
- Desarrollar un algoritmo recursivo que implemente la estrategia voraz.
- Convertir el algoritmo recursivo a uno iterativo.
Notas y referencias
Campos, J. (2021). Algoritmos voraces. Universidad de Zaragoza. http://webdiis.unizar.es/asignaturas/AB/material/2-Algoritmos Voraces.pdf
Métodos probabilísticos -Algoritmos aleatorios-
Si un algoritmo, que además de su entrada, usa un generador de números aleatorios o toma decisiones aleatorias en su ejecución, entonces es aleatorio, cuando solo depende de su entrada es determinista. En la práctica, usamos generadores pseudoaleatorios. El tiempo de ejecución y, en otros casos su salida, no son fijos para una entrada dada.
Ejemplos
Ejemplo 1 Algoritmos de Las Vegas (LV)
Entrada. Una secuencia de n elementos , el elemento y pertenece a la sequencia.
Salida. tal que .
buscar_el_elemento(a, A)
i = 0
while A[i] != a
i = RANDOM(0, A.length) # 0 <= i <= A.length, i es aleatorio
return iEjemplo 2 Algoritmos de Monte Carlo (MC)
Entrada. Una secuencia de n elementos , el elemento y el límite de iteraciones.
Salida. tal que .
buscar_el_elemento(a, A, k)
for i=0 to k
j=RANDOM(0, A.length) # 0 <= j <= A.length, j es aleatorio
if A[j] == a
return jNotas y referencias
Karp, R. M. (1991). An introduction to randomized algorithms. Discrete Applied Mathematics, 34(1-3), 165-201.
Wootters, M. (2022, May 17). Class 1, Video 1: Introduction. Youtube. Retrieved from https://www.youtube.com/watch?v=01ohO542NMI&list=PLkvhuSoxwjI_JL7GYcJHK7-EK55t0KYGO&ab_channel=MaryWootters
Algoritmos de aproximación
Una amplia variedad de problemas importantes son NP-completos (horario de trabajo, el problema del viajero o vendedor, ...), entonces no podemos sencillamente abandonarlos porque no sabemos algoritmos que lo resuelvan en tiempo polinomial. Para esto, diseñamos algoritmos con tiempo polinómico que se acercan a la solución por un factor: radio de aproximación tal que
donde es el costo de la solución óptima y es el costo de producido por el algoritmo. Algunos tambien a estos algoritmos heúristicos.
Corutinas
Co-routines as an alternative to state machines - Eli Bendersky's website. (2022, September 17). Retrieved from https://eli.thegreenplace.net/2009/08/29/co-routines-as-an-alternative-to-state-machines
Recursión mutua
Máquinas de estado
Iteradores
Generadores
Stream (pattern observer)
Preguntas frecuentes
¿Todos los algoritmos recursivos siguen un enfoque divide y vencerás?
No.
¿Estas técnicas son mutuamente excluyentes, esto es, si puedo aplicar una, no puedo aplicar las otras?
Son mutuamente excluyentes.
La RAE no recoge el verbo memoizar ni la memoización, debe ser memorizar y memorización
Notebook
Algoritmos sobre grafos
Representación o ¿qué estructura de grafos usamos?
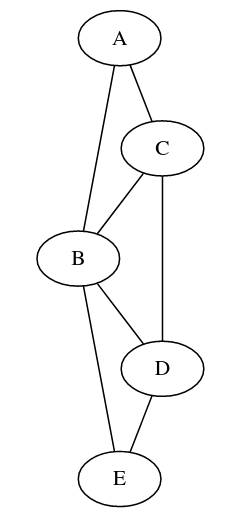
{
"A": {"B", "C"},
"B": {"A", "C", "D", "E"},
"C": {"A", "B", "D"},
"D": {"C", "B", "E"},
"E": {"D", "B"}
}def solve(s)
if s is solution
yield s
for x in s
yield from solve(x)| Matriz de adyacencia | Tabla Hash | Lista de adyacencia | Orientado a objetos | Usando los mecanismos del lenguaje | |
| Comentarios | Para grafos pequeños suele ser la preferida porque es más simple. | Usando en vez de listas tablas hash, conseguimos saber si dos vertices son adyacentes en O(1). | En espacio es más eficiente que la matriz de adyacencia. | Para guardar atributos como el nombre, distancia, costo, … usamos este enfoque. | Dependiendo el problema volver visible el grafo u otras estrcturas de datos y crear una copia de cada intento de solución no es lo más eficiente, así podemos usar los mecanismos del lenguaje (por ejemplo, pila de recursividad en vez de nosotros crear nuestra pila). |
Elementales
Maneras de atrevesar un árbol:
- In-order traversal (LVR)
- Reverse order traversal (RVL)
- Preorder traversal (VLR) -DFS-
- Postorder traversal (LRV)
- Normal Level Order Traversal -BFS-
BFS
BFS es un algoritmo que recorre todos los hijos de un nodo A y continua con sus hijos.
frontier = Queue()
visited = {}
while frontier is not empty:
node = frontier.pop()
if node not in visited:
visited.add(node)
for each child of node's children:
node.relax(child)
frontier.push(child)
return failedDFS
Depth-first search, también llamado Backtracking [1], Euler tour o recorrido en orden si es un árbol, es un algoritmo que recorre el nodo más profundo, regresa al primero de la pila (el padre) y continua con el siguiente nodo. Este algoritmo suele ser presentado en su forma recursiva, porque así se ahorra implementarlo, esto es, sustuimos nuestra pila por la pila de recursividad.Tg
PseudoDFS
frontier = Stack()
visited = {}
while frontier is not empty:
node = frontier.pop()
if node not in visited:
visited.add(node)
for each child of node's children:
node.relax(child)
frontier.push(child)
return failedConvierte el DFS a una versión iterativa usando pilas.
class DepthFirstSearcher: def __init__(self, graph): self.graph = graph self.records = set() def explore(self): found = False for vertex in self.graph.vertices(): if vertex not in self.records: found, v = self.visit(vertex) if found: return found, v def visit(self, vertex): stack = [] v = vertex while True: pivot = v while v != None: while v != None and v not in self.records: stack.append(v) self.records.add(v) if len(stack) >= 2: self.graph.setEdge(stack[-2], stack[-1]) if self.graph.isAGoal(v): return True, v pivot = v v = self.graph.exploreNeighbor(v) v = self.graph.exploreNeighbor(pivot) stack.pop() self.graph.finish(v) if len(stack) == 0: return False, None v=self.graph.exploreNeighbor(stack[-1])💡Otra solución es un pseudo DFS que cambia una cola a una pila en el algoritmo BFS. https://stackoverflow.com/questions/20429310/why-is-depth-first-search-claimed-to-be-space-efficient
Algoritmo
Note que si realizamos una evaluación al nodos para obtener una solución es un problema de búsqueda.
frontier = Frontier()
visited = {}
while frontier is not empty:
node = frontier.pop()
if isGoal(node):
return path_to_node
if node not in visited:
visited.add(node)
for each child of node's children:
node.relax(child)
frontier.push(child)
return failedDAG
DAG aplicaciones
Merkle DAGs. IPFS, Git, … Content linking via directed acyclic graphs (DAGs).
Topological Sorting
Aplicaciones
Si necesitar calenderizar con requisitos, Topological Sorting tiene sentido. Aunque más generalmente, Feedback arc set.
Makefile
a: b c
@echo "A"
b: c
@echo "B"
c:
@echo "C"Al ejecutar make obtenemos
C
B
A¿Por qué? Dibujemos el grafo:
graph TD
C --> B
C --> A
B --> AEjecute el Topological Sorting.
Pruebe con la utilidad de Unix: tsort.
Revisar la Herencia orientado a objetos.
Revisión y ejecución de Dependencias.
Notebook
Laberinto
Crea tus propios algoritmos para conseguir ir del punto A al punto B en un un laberinto.
https://graph-theory.sanchezcarlosjr.com/
Notas y referencias
[1] https://arxiv.org/pdf/cs/0011047.pdf. En esto puede llegar a existir confusión.
Preguntas frecuentes
¿Existe un compendio de todos los teoremas, definiciones, ...?
https://people.math.sc.edu/cooper/math776/StudyGuide.pdf
¿Red o grafo?
Grafo es el concepto abstracto matemático.
Red es el grafo que representa objetos del mundo real, los nodos son entidades del sistema y las aristas representan la relacion entre ellos.
Sin embargo, en la literatura puedes encontrarlos indistintamente.
https://bence.ferdinandy.com/2018/05/27/whats-the-difference-between-a-graph-and-a-network/
https://arxiv.org/pdf/1302.4378.pdf
http://networksciencebook.com/
¿Existen base de datos que guarden grafos?
Sí, este tipo de base de datos ya tienen integrados los algoritmos vistos aquí. .
Notas y referencias
Para aprender de manera visual teoría de grafos: https://d3gt.com/unit.html, usar el apéndice de CLRS, o el libro Frank Harary. Graph Theory. Addison-Wesley, 1969.
Ensayo sobre la representación de grafos: https://www.python.org/doc/essays/graphs/
Network Time Protocol
Introducción a la Teoría de la Computación
Complejidad computacional
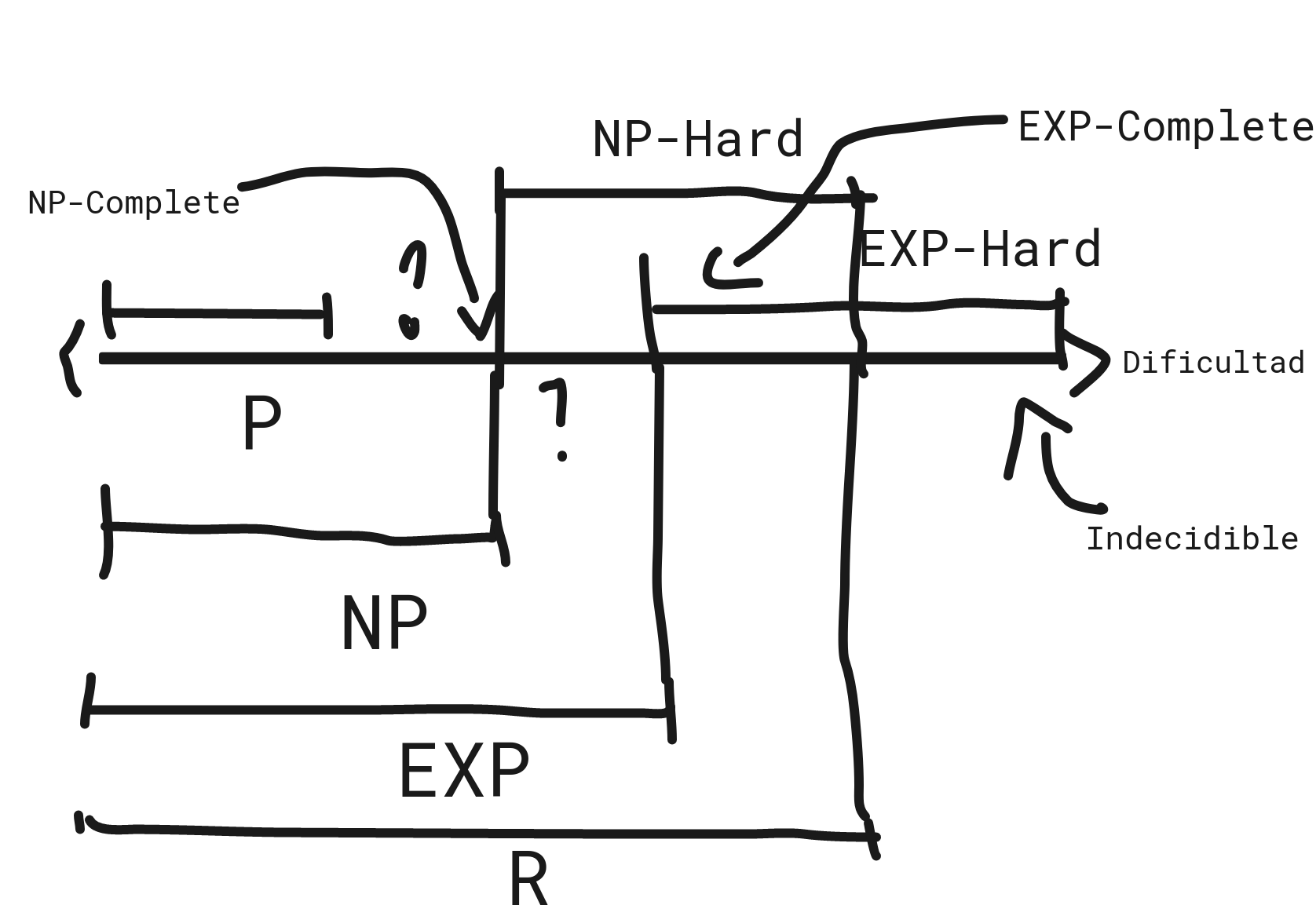
SAT
Aplicaciones
Sodoku.
Teorema Cook-Levin
Notas y referencias
https://plato.stanford.edu/entries/computational-complexity/
¿Qué es lo que sigue? ¿Cuál es el estado del arte?
Algoritmos heúristicos
Algoritmos paralelos
Hilos y procesos hijo.
Model Actor
Async
Geometria computacional
MapReduce
Algoritmos cuánticos
Operaciones asíncronas
Sincronas.
Asincronas.