
Theory of Computation
Requisites
Resources
Foundations
- Olivia Gutú, Lenguajes formales y autómatas, Universidad de Sonora (PDF)
- Domingo Gómez, Luis M. Pardo, Teoría de Autómatas y Lenguajes Formales (para Ingenieros Informáticos) (PDF)
- Elena Jurado, Teorías de Autómatas y Lenguajes Formales (PDF)
- Leopoldo Altamirano, Miguel Arias, Jesús González, Eduardo Morales, Gustavo Rodrı́guez, Teorı́a de Autómatas y Lenguajes Formales (PDF)
- Sergio Balari, TEORÍA DE LENGUAJES FORMALES Una Introducción para Lingüistas (PDF)
Lenguajes Formales y Autómatas. (2020, January 19). Retrieved from https://turing.iimas.unam.mx/~ivanvladimir/page/curso_lfya_2022i
Welcome to maquinas’s documentation! — ⚙️ maquinas 0.1.5.14 documentation. (2023, January 23). Retrieved from https://maquinas.readthedocs.io/en/stable
History
| Name | Tags |
|---|---|
| Machines, Languages, and Computation at MIT | Peter J. DenningTheoretical Models of Computationanecdotes |
| Lectures on computation | Richard P. Feynman |
References
Introduction
What is the Theory of computation?
mathematical cybernetics
Why does the Theory of computation matter to you?

Research
Ecosystem
Standards, jobs, industry, roles, …
Story
FAQ
Worked examples
Models of computation
https://gist.github.com/sanchezcarlosjr/333b9a774c0fa57f55532d772b13c946
https://cs.brown.edu/people/jsavage/book/pdfs/ModelsOfComputation_Chapter4.pdf
Model of computation
| Automaton (Mathematics model) | Paradigm |
| Turing Machine | Imperative (procedural) programming |
| Lambda-calculus | Functional programming |
| Pi-calculus | Event-based and distributed programming |
| OOP | |
| Logic |
Mind and computation
https://en.wikipedia.org/wiki/Talk:Theory_of_computation
Strings and Languages
Definitions.
Alphabet. Any non-empty finite set. We generally use either capital Greek letters , or uppercase letters to designate alphabets.
Symbol. The members of an Alphabet.
Examples:
String over an alphabet. A finite sequence of symbols from that alphabet.
Length of a string. If is a string over , the length of , written , is the number of symbols that it contains. Some authors prefer to use for indicating some characteristic applied on .
Empty string.
Language. Set of strings. We generally use upper-case letters to designate languages.
Lexicographic ordering.
1. Shorter strings precede longer strings.
2. The first symbol in the alphabet precedes the next symbol.
Regular operations.
Let be languages:
Union:
Concatenation:
Kleene star: , note always.
Kleene plus:
Example. Let and
Chomsky hierarchy
Regular languages
Operator precedence
| Operator | Precedence |
| () | 6 |
| *+? | 5 |
| concatenation | 3 |
| | | 2 |
| | 1 |
Examples:
ax|b → (ax)|b
ab*|c → (a(b*))|c
ab?* → a((b?)*)
ab*? → a((b*)?)
Note: L(a((b?)*)) = L(a((b*)?))
If two operators have the same precedence, then they generate the same language. ??
TODO: 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac'.match(/^(a+)+b/)
Regular Expressions
Pathological regular expressions can execute in geometric time. For example 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac'.match(/^(a+)+b/) will effectively crash any JavaScript runtime. JS-Interpreter has a variety of methods for safely dealing with regular expressions depending on the platform. https://neil.fraser.name/software/JS-Interpreter/docs.html
Worked examples
If is a string, then denotes the reversal of . If and are strings, then
Finite state machine
Representations.
Moore and Mealy. Responses are all kinds of values.
DFA and NFA. Responses are 0 or 1.
Programming.
Worked examples
- Make a program in C++ that verify emails by argument (Hint: use the library regex).
Moore and Mealy automata
Boolean Algebra and Digital Logic. Circuit conversion. From Moore to Circuit.
https://www-igm.univ-mlv.fr/~berstel/Exposes/2009-06-08MinimisationLiege.pdf
Finite automata
Finite automata and their probabilistic counterpart Markov chains. Finite Automaton (FA) or Finite-State Machine. An automaton (Automata in plural).
- The computer is complex, instead, we use an idealized computer called a computational model.
- A finite automaton:
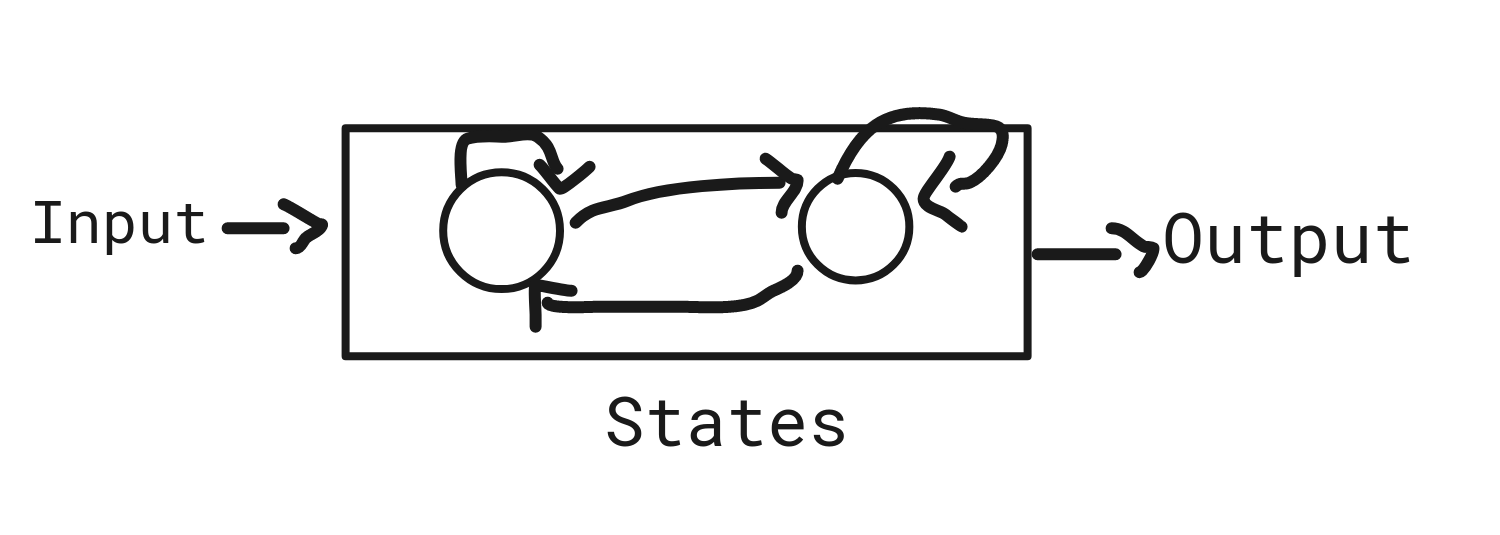
We feed the input string to the machine , the processing proceeds as follows:
- Start in state .
- Read 1, follow the transition from to .
- Read 1, follow the transition from to .
- Accept because is in an accept state at the end of the input.
The formal definition of a deterministic finite automaton (DFA)
A finite automaton is a 5-tuple where
- is a finite set called the states,
- is a finite set called the alphabet,
- is the transition function,
- is the start state, and
- is the set accept states, they are sometimes called final states.
The formal definition of a nondeterministic finite automaton (NFA)
A finite automaton is a 5-tuple where
- is a finite set called the states,
- is a finite set called the alphabet,
- is the transition function (P is a power set),
- is the start state, and
- is the set accept states, they are sometimes called final states.
Converting NFAs to DFAs
Rabin-Scott Theorem
https://twitter.com/getjonwithit/status/1720832283026854098
delta = {
'state1': {
'symbol1': {'state1', 'state2',...}
}
}
# BFS
NFAToDFA(NFA)
Classification
- Acceptors
- Transducers
- Generators (also called sequencers)
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/40342.pdf
Worked examples
Cellular automaton
FAQ
What is the difference between finite automata and finite state machines?
Pattern Matching
https://www.seas.upenn.edu/~lee/10cis541/lecs/EFSM-Code-Generation-v4-1x2.pdf
Regular expressions. Regex.
Regular expressions, in short regex, are expressions that generate regular languages.
Although some modern regex engines support regular expressions, they support nonregular languages (Regular Expression Recursion) too. It can be misleading, but we use the above definition forward.
POSIX regular expressions. BRE (Basic Regular Expressions), ERE (Extended Regular Expressions), and SRE
Flavors. Perl and PCRE.
https://gist.github.com/CMCDragonkai/6c933f4a7d713ef712145c5eb94a1816
Regex engine.
perl vs awk
Accepters are equivalent to regular expressions
Are traducers equivalent to regular expressions?
/^1?$|^(11+?)\1+$/
Worked example
Let a regular expression , make a new regular expression that removes from generated language.
XYZ|XZ|YZ|XZ|X|Y|Z
Write an algorithm to generate a regex for detect a number
Generate the language L from a given regex.
Make an expression on PCRE 4.0 or above that checks if a string is a palindrome.
Tools
AWK
Roman numbers: https://wiki.imperivm-romanvm.com/wiki/Roman_Numerals
Make a program that converts roman numbers to Arabia numbers using regular expressions.
https://github.com/sanchezcarlosjr/compilers-uabc/blob/main/lexer-awk/roman_to_arabig.awk
RegEq
Check equivalence of regular expressions
https://bakkot.github.io/dfa-lib/regeq.html
https://regex-equality.herokuapp.com/
Goyvaerts, J. (2022, December 02). Regular Expressions Reference. Retrieved from https://www.regular-expressions.info/reference.html
Regular expressions to Automata. Generalized nondeterministic finite automaton. Arden’s Rule.
Regular expressions to Automata
- Generalized nondeterministic finite automaton.
def convert_to_regular_rxpression(G):
if G.number_of_states == 2:
return - Solving right-linear equation by Arden’s rule.
https://assets.press.princeton.edu/chapters/i11348.pdf
https://www.gwern.net/docs/math/1973-knuth.pdf
Steps to convert regular expressions directly to regular grammars and vice versa

Free Grammars. LL.
Deterministic context-free languages.
FAQ
Are axioms in math equivalent to production rules in unrestricted grammars?
how could a CFG hold an unrestricted grammar (UG), which is turing complete?
https://stackoverflow.com/questions/61952877/chomsky-hierarchy-examples-with-real-languages?rq=1
Notes and references
[1] M. Johnson, “Formal Grammars Handout written,” 2012 [Online]. Available: https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/handouts/080 Formal Grammars.pdf. [Accessed: 28-Feb-2022]
Grammar
We describe the syntax of language as grammar but not semantics.
Definition
A grammar is a 4-tuple
where is a finite set of objects called variables or nonterminals,
is a finite set of objects, disjoint from , called terminal symbols, in short terminals, and sometimes tokens because it is a terminal identifier.
is a special symbol called the start variable,
is a finite set of rules, called production rules, with each rule being a variable a string of variables and terminals.
If production rules are of the form
where , . Some authors call x and y Head and Body respectively. Others call x and y left-hand side (LHS) and right-hand side (RHS).
The production rules are applied in the following manner: Given a string
| Rule | Application | Result |
| | | |
We say that derives o that is derived from .
A rule can be used whenever it’s applicable.
If
we say that derives and writes
. The * indicates an unspecified number of steps (including zero).
Informally, grammar consists of terminals, nonterminals, a start symbol, and productions.
- Terminals.
classDiagram
class TerminalSymbol
TerminalSymbol : token // id or name
TerminalSymbol : lexeme // regular expression- Nonterminals are syntactic variables that can be replaced, so they denote a set of strings.
- Start symbol.
- Productions. We may follow a notation for production rules, which is a particular form.
BNF. A particular form of notation for grammar (Backus-Naur form).
CNF. A particular form of notation for grammar (Chomsky normal form).
Bottom-up
graph LR
subgraph scanning
W -. find the body X that match w=uXv .-> Body
end
subgraph substitution
Body -. substitute body X to head Y, w=uYv.-> Head
Head -- search if it is not StartSymbol --> W
endBacktracking.
Chomsky normal form (CNF) example
, ,
Backus–Naur form (BNF) example
, ,
Derivations
Parse trees and derivations
Ambiguity
Writing a grammar
Verifying the language generated by a grammar
The language generated by . Let be a grammar. Then the set
is the language developed by G.
Grammar Hierarchy
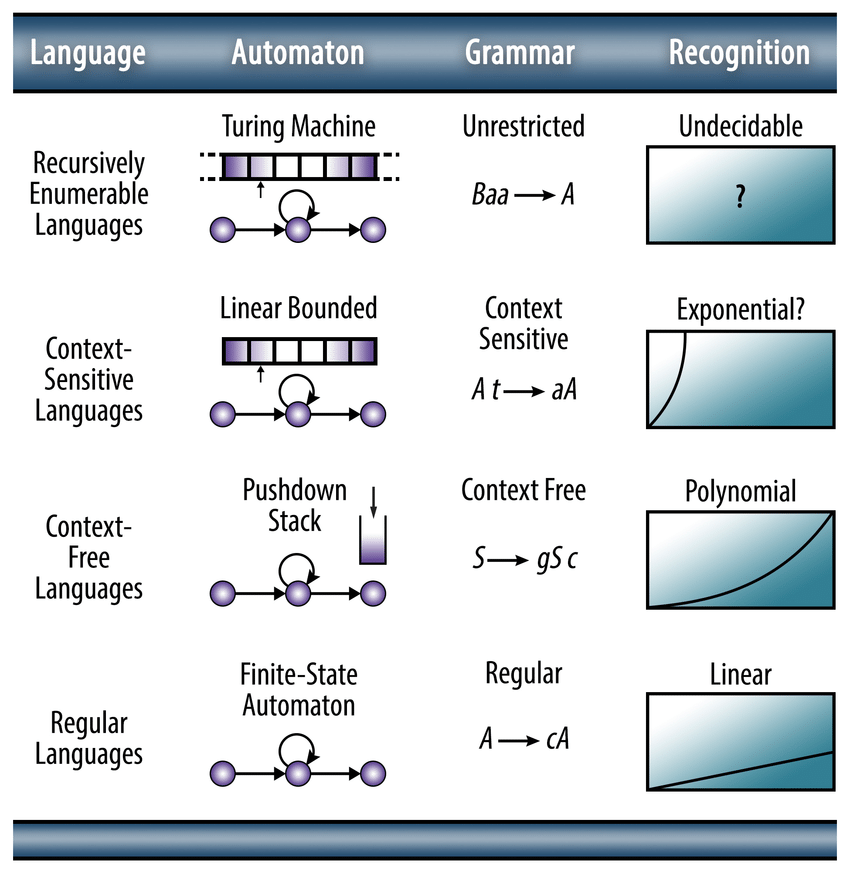

Set view
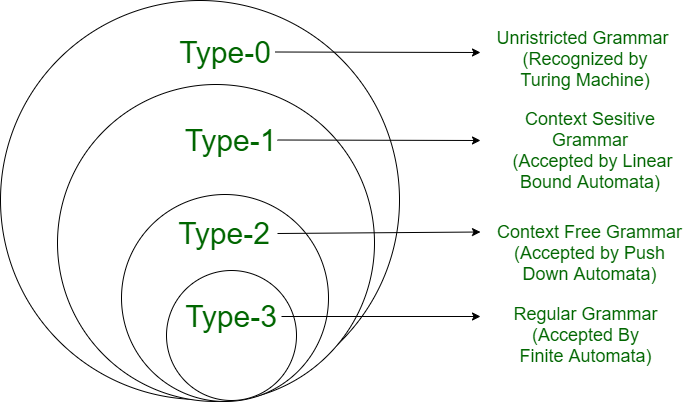
Table view
| Grammar type | Grammar accepted | Language Accepted | Automaton | Production rule form |
| Type 0. These are the most general. | Free or unrestricted grammar | Recursively enumerable language | Turing Machine | , where both u and v are arbitrary strings of symbols in V, with u non-null. |
| Type 1 | Context-sensitive grammars | Context-sensitive language | Linear-bounded automaton | where ,, and are arbitrary strings of symbols in , with non-null, and a single nonterminal. In other words, in a particular context. |
| Type 2 | Context-free grammars | Context-free language | Pushdown automaton | , where is an arbitrary string of symbols in , and is a single nonterminal. i.e. regardless of context. |
| Type 3. These grammars are the most limited in terms of expressive power. | Regular grammars | Regular language | Finite-state automaton | , (right-regular grammar), (left-regular grammar), , where and are nonterminals and is a terminal. Regular grammar is either right-linear grammar or left-linear grammar, but not both. Mixing left-regular and right-regular rules are the context-free grammar. |
https://www.cs.utexas.edu/users/novak/cs343283.html
Augmented Grammar
Definite clause grammars
Worked examples
Automata and Grammar
Context-free grammars
TODO: Context-Free Grammars Versus Regular expressions
Classification
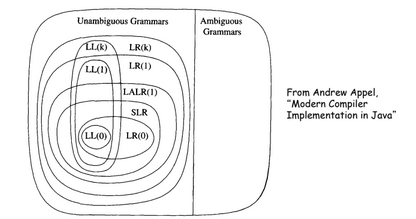
Notional conventions
Derivations
Ambiguity
- Conversión de gramáticas ambiguas a no ambiguas.
- Estrategias para el manejo de la ambigüedad en los lenguajes.
- Problemas equivalentes a determinar si una gramática es ambigua.
- Complejidad de determinar si una gramática es ambigua.
Writing a grammar
Eliminating Ambiguity
Elimination of Left Recursion
A left recursive grammar has a nonterminal such that there is a
derivation for some string
Top-down parsing methods cannot handle left-recursive, so
Method.
Given a grammar, you replace each left-recursive pair of productions
by
Example.
We replace recursive pair of productions following the method by
General Algorithm.
References
Elimination of Left Recursion. (2021, October 31). Retrieved from https://cyberzhg.github.io/toolbox/left_rec
L-system or Lindenmayer system
https://runestone.academy/ns/books/published/thinkcspy/Strings/TurtlesandStringsandLSystems.html
Left Factoring
Non-Context-Free Language Context
Computability theory
Turing Machine
Undecidable problems
Reductions
Reduce the test question as “what’s the next number in this sequence” into polynomials.
https://twitter.com/b_subercaseaux/status/1622433295807172609
FAQ
Continuous "recursive iteration"
Self-replicating programs. Quine functions (computing).
intron functions computing
function twice(x) {
console.log(x); // Action
console.log("'" + x + "'"); // Template
}
// If language allows read function code
twice(twice.toString())
// If language doesn't allow read function code
twice("function twice(x) {console.log(x);console.log(\"'\" + x + \"'\")}")
// Full Self replication
function self_reply() {
function twice(x) {
console.log(x); // Action
console.log("'" + x + "'") // Template
}
twice(twice.toString()+"\ntwice(twice.toString())") // Execution
}
// Another option
function self_reply() {
A = f.toString() // Template
function f() {
console.log("MY Instructions"); // Payload
console.log(A+"f()"); // Reflection, Reproduction, and mutation
}
f()
}
// Another option
(function quine() {
console.log(quine.toString());
})();
// Other option
$=_=>`$=${$};$();$()`Conferences, N. (2020, February 26). The Art of Code - Dylan Beattie. Youtube. Retrieved from https://www.youtube.com/watch?v=6avJHaC3C2U&ab_channel=NDCConferences
Fridman, L. (2020, July 11). Self-replicating Python code | Quine. Youtube. Retrieved from https://www.youtube.com/watch?v=a-zEbokJAgY&ab_channel=LexFridman
Computational complexity theory
A high-level overview of NP
NP
NP are all languages where one can verify membership quickly.
NP are all languages where one can test membership quickly.
Certificate concept.
Does
Cook-Levin Theorem: . Proof later.
Def.
Theorem.
Not always “good” algorithms to solve problems. But many problems we think about can be checked in polynomial time or solved by brute force in exponential time.
NP-Completeness
Schema of reductions.
TODO: A Boolean formula is in CNF that consists of literals (a variable or a negated variable) and clauses (an OR of literals).
, a special case of SAT.
A clique in a graph is a collection of points that are all pairwise connected by lines. k-clique in a graph is a subset of k nodes all directly connected by edges.
Theorem.
We’re going to reduce the 3SAT problem into CLIQUE.
Reduction.
Nodes are literals.
Edges. G has all non-forben deges.
Algorithms
WalkSAT
Cook-Levin Theorem
References
https://www.claymath.org/sites/default/files/pvsnp.pdf
References
https://www.cs.toronto.edu/~sacook/math_teachers.pdf
FAQ
If we have an input has a size S(n), does our algorithm has to be at least the size, formally ? Suppose the permutations of a string with , it have permutations, so our algorithm checks the relation .
No. Sometimes you can write an algorithm .
Graph grammars
Introduction to graph grammars with applications to semantic networks
P system
The Rough P System: Simulation of Logic Gates and Basic DB Tasks using Rough P System
TODO
“We tend to forget that every problem we solve is a special case of some recursively unsolvable problem!” Knuth, D. E. (1973). The dangers of computer-science theory. In Studies in Logic and the Foundations of Mathematics (Vol. 74, pp. 189-195). Elsevier.
21] D.E. Knuth, On the translation of languages from left to right, Information and Control 8 (1965) 607–639.
[22] D.E. Knuth, A characterization of parenthesis languages, Information and Control 11 (1967) 269–289.
Rice’s theorem