Examen 4
Describa las principales secciones de la memoria asignada a un programa durante su ejecución.
La respuesta: Típicas secciones de la memoria en tiempo de ejecución
+--------------+ Direcciones bajas.
| | El tipo de archivo (por ejemplo .ELF), librerías estáticas, ...
| Code | Donde las instrucciones de nuestro programa viven.
| Static | Constantes. Datos generados por el compilador.
| Heap | Memoria dinámica para estructuras de datos. Crece positivamente.
| ↓ |
| ↓ |
| |
| |
| Free memory | Memoria libre. Bloques de memoria de 4KB o 16KB con basura.
| |
| |
| |
| ↑ |
| ↑ |
| Stack | Guarda los "activation records". Crece negativamente.
+--------------+ Direcciones altas.En el caso del Heap, dinámico significa que localización y deslocalización es hecha explíticitamente desde un procedimiento mientras la aplicación está corriendo. En otras palabras, no sabemos cuánta memoria se necesita. Típicas operaciones que incrementan el Heap son «new» (instanciar una clase) y malloc. Por su puesto, debemos considerar la liberación (free) del espacio: no queremos acabarnos con la memoria disponible ni queremos errores inesperados. Por esto nace la necesidad de un Gargabe Collector, una característica de los lenguajes modernos para deslocalizar objetos no usados.
El stack (call stack) es donde almacenamos el estado actual (activation records) de un bloque de código (funciones, procedimientos, métodos,…) y un registro del historial de las llamadas (main llama a g, g a f, f a r, …). Debes considerar que algunos lenguajes de programación como Erlang también pueden usar colas en lugar de pilas.
El temido Stack Overflow surge precisamente cuando agotamos el espacio disponible para esta estructura de datos. Este error es normalmente causado por la recursión, aunque puede ocurrir sin ella: con una gran cantidad de llamadas o con un ciclo de llamadas. Por ello, algunos lenguajes de programación como Java (java -Xss1m MyProgram) permite cambiar el tamaño de la pila.
Es importante mencionar que este acercamiento a la recursividad no es el único, por ejemplo, el uso de iteradores y generadores en lenguajes como Python o Haskell.
Las estructuras de datos «activation records» las estudiamos en la siguiente pregunta.
Contexto
Antes de hablarte sobre las secciones de la memoria, debemos entender que el manejo de la memoria es contigente: existen mundos posibles con otra ingenería. Por ejemplo, al inicio toda la memoria era solo para un solo proceso, luego para el sistema operativo y para un proceso, hasta llegar nuestros días con la virtualización y múltiples procesos.
Con esto en mente, estudiemos el trabajo actual de los maestros de todos nosotros [1]: primero discutimos la memoria de arriba a abajo brevemente, para luego enfocarnos exclusivamente en el ambiente en ejecución -cuando nuestro programa es un proceso-.
Tenemos una jeraquía de memoria, pero para la programadores principalmente existen los registros de la CPU, la memoria principal y la secundaria. Y por otra parte, el sistema operativo que debe lidiar con múltiples procesos. Así nace la necesidad de virtualizar la memoria: nuestros programas son más fáciles de crear o usar, da mayor protección de la intervención de otros procesos y los aisla de los fallos de otros procesos.
La colaboración entre estos 3 componentes ocurre con la ayuda de la MMU (en español, memoria de manejadora de memoria), una tabla de páginas o segmento (bloque de memoria regularmente de 4KB o 16KB) y el concepto de memoria virtual.
Aquí empieza la diversión.
Nuestro programa en ejecución no se entera de el cómo está organizada la memoria porque cada dirección de memoria es un dirección virtual. ¡Ya no tenemos que preocuparnos por donde guardamos nuestras variables! Como escritores de un compilador, un problema menos. Podemos asumir que los bloques son contiguos.
El sistema operativo asigna a nuestro programa cuando entra en ejecución una abstracción de la memoria física llamado espacio de memoria.
Una típica subdivisión o disposición de la memoria en tiempo de ejecución fue explicada en la sección anterior.
[1] Ken Thompson creó Unix entre 3 semanas, ¿acaso eso no es ser un maestro?
Federation, V. C. (2019, May 06). Ken Thompson interviewed by Brian Kernighan at VCF East 2019. Youtube. Retrieved from https://www.youtube.com/watch?v=EY6q5dv_B-o&t=1909s&ab_channel=VintageComputerFederation
Mencione qué es un “Activation Record” y para qué se utiliza.
Un «Activation Record» (stack frame, call frame o solamente frame) es una estructura de datos usada en ejecución para almacenar las llamadas a un bloque de código (funciones, procedimientos, métodos, …), donde el registro completo de llamadas es guardado en la call stack. Un general activation record es:
struct ActivationRecord {
current paramaters
returned values
control link
access link
saved machine status
local data #Los valores internos del bloque.
temporaries
}- Los valores temporales son aquellos que no pueden ser guardados en registros.
- Guardamos el estado de la máquina para referirnos a la información previa a la llamada, como por ejemplo, la dirección de retorno.
- Los access links es donde guardamos la información de otros activation records.
- Los control links apunta a la dirección de memoria de la llamada.
- Si el bloque de código regresa un valor, necesitamos un espacio de memoria para eso. Aunque, también podemos guardarlo en un registro.
- Los argumentos usados en el método actual. Aunque, también pueden estar en un registro.
Utilizamos los «Activation Record» en ejecución para que la subrutina actual acceda a la información interna, interactúe con otras subrutinas, y por supuesto, es un mecanismo que habilita la recursividad.
Explique las ventajas de utilizar “Stack Machine” como modelo de evaluación.
Los programas son más compactos en el modelo “Stack Machine”, además es más fácil de implementar por ser un modelo bastante intuitivo. Este modelo es flexible porque permite adaptarlo sin mucho problema a las necesidades de tipos y operaciones. Incluso es posible combinarlo con otros modelos como “Register Machine”, “Functional evaluation model”, “rule-based evaluation model”, y “constraint-based evaluation model”.
Dependendiendo de la arquitectura de la computadora, también puede ser bastante eficiente.
Suponga que queremos agregar la siguiente expresión condicional a COOL:
cond <p1> => <e1>; <p2> => <e2>; … ; <pn> => <en>; dnoc
Suponga que n >=1, y que se inicia evaluando el primer predicado <p1>, en caso de ser verdadero se evalúa la expresión <e1>, de lo contrario evalúa <p2>, y así sucesivamente hasta que uno de los predicados se cumple o termina de evaluarlos a todos.
Escriba la función de generación de código cgen(cond <p1> => <e1>; … ; <pn> => <en>; dnoc) siguiendo la “Stack machine” y las convenciones MIPS vistas en las lecturas.
Solución:
# Kind of Predicates
codegen(expression1 = expression2, tag) =
codegen(expression1)
sw $a0, 0$sp # push $a0
addiu $sp, $sp, -4 # new space in stack
codegen(expression2)
lw $t1, 4($sp) # pop
addiu $sp, $sp, 4 # remove space in stack
beq $t1, $a0, tag
codegen(expression1 != expression2, tag) =
codegen(expression1)
sw $a0, 0$sp # push $a0
addiu $sp, $sp, -4 # new space in stack
codegen(expression2)
lw $t1, 4($sp) # pop
addiu $sp, $sp, 4 # remove space in stack
bne $t1, $a0, tag
...
# We don't manipulate the stack. We keep the principle.
codegen(cond <p1> => <e1>; … ; <pn> => <en>; dnoc) =
codegen(p1, e1) # beq $t0, $a0, e1; bne $t0, $a0, e1; ...
codegen(p2, e2)
codegen(p3, e3)
codegen(p4, e4)
...
codegen(pn, en) # beq $t0, $a0, en; bne $t0, $a0, en; ...
# $a0 is gargabe
li $a0, $0
b end_cond
e1:
codegen(e1)
b end_cond
e2:
codegen(e2)
b end_cond
e3:
codegen(e3)
b end_cond
...
en:
codegen(en)
b end_cond
end_cond:
Seguimos la notación un poco más exacta de:
12-02: Code Generation I (17m26s) | Week 7: Code Generation & Operational Semantics | Compilers | edX. (2022, December 01). Retrieved from https://learning.edx.org/course/course-v1:StanfordOnline+SOE.YCSCS1+2T2020/block-v1:StanfordOnline+SOE.YCSCS1+2T2020+type@sequential+block@5dbc1371fbcb4f1497da952a991d7387/block-v1:StanfordOnline+SOE.YCSCS1+2T2020+type@vertical+block@1d1d0ef7cac943f1b6d22afce44845f0
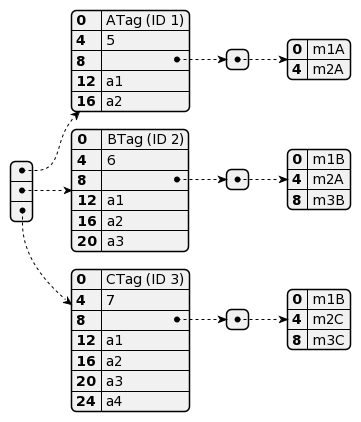
Considere las siguientes clases:
| class A { a1 : Int; a2 : String; m1() : Object { ... }; m2() : Object { ... }; }; | class B inherits A { a3 : Int; m1() : Object { ... }; m3() : Object { ... }; }; | class C inherits B { a4 : Int; m2() : Object { ... }; m3() : Object { ... }; }; |
Ilustre la estructura de los objetos de tipo A, B y C, incluyendo tablas de dispatch.