
Computer vision and Image processing
Requisites
Introduction
What is Computer vision?
Computer vision or digital image processing is not Computer graphics, the latter are synthetic images, that is, we model, visualize, generate images by a computer.
https://courses.cs.washington.edu/courses/cse576/23sp/notes/1_Intro23.pdf
Why does Computer vision matter to you?
The expense associated with developing and implementing computer vision systems is justified by the immense value it offers. Its applications vary widely in terms of the sophistication of their "intelligent" observations. These include:
Low level vision
- Measurement
- Enhancements
- Region segmentation
- Features
Mid level vision
- Reconstruction
- Depth
- Motion Estimation
High level vision
- Category detection
- Activity recognition
- Deep understandings
Understanding why vision is challenging necessitates delving into a myriad of issues such as ill-posed problems, viewpoint variations, illumination conditions, occlusion, scale, deformation, background clutter, intra-class variation, local ambiguity, and deciphering the world behind the image.
Research
Ecosystem
Standards, jobs, industry, roles, …
OpenCV
YOLOv7
Distilled YOLOV7
UNET v7
https://pypi.org/project/face-recognition/
https://huggingface.co/docs/transformers/main/model_doc/sam
Datasets
ESA/NASA Hubble. Datasets for education and for fun. https://esahubble.org/projects/fits_liberator/datasets/
Story
FAQ
Worked examples
Image formation
stimulus
passive sensing
active sensing
feature
feature extraction
object model
rendering model
The two core problems of computer are reconstruction and recognition, however we have a lot of other changes such as view point variation, illumination, occlusion, scale, deformation, background clutter, object intra-class variation, local ambiguity, the world behind the image
Digital image processing
A gray image is a function that gives the light intensity at position and a rectangle . Similarity, a color image is a vector-valued function: , where we call the components as channels or planes, that is, a 3-channel color image ia mapping from a 2-dimensional space of locations to a 3-dimensional space of color intensity values . However, in computer vision, we operate on digtal images (aka. discrete images): sample the 2D space on a regular grid (discrete pixels at locations) and quantize each sample (round to nearest integer such as 16-bit, 12-bit, 8-bit images). Thus, image is represented as matrix of integer values. Programming Languages represent those integers as uint16 and uint8, that is, unsigned integer 16 bits [0,65535] and unsigned integer 8 bits [0,255].
If you think an image as function or matrix you could apply its mathematical operators to them.
Noise in images is another function that is combined to an original to another function.
Salt and peper noise: random ocurrences of black and white pixels.

Impulse noise: random ocurrences of white pixels
Gaussian noise: normal random noise
Preserve image difference
How can you guarantee that difference between images be uint8 and be an absolute difference?
doesn’t work because we must consider clamp in every simple operation, that is, . For example, suppose two pixels of both images in interval mentioned before:
But we want an such that , e.g.
Let a function that must applied in every operation (abs, -, +) , the solution is .
Proof.
If , (the argument is negative so applying clamp gives us 0) and (the argument is a number between 0 and 255 so applying clamp gives us b-a). Similar argument for .
c = clamp(0,255)
g = (a,b) => Math.abs(c(c(a-b)+c(b-a)))
g(20,56) // 36
g(56,20) // 36
g(0,257) // 255
g(300,0) // 255
g(-10,-11) // 1
g(100,25) // 75
g(25,100) // 75Another option is transforming values to floating point (so, you can think numbers as real numbers informally).
Clamp
// limits=[0,255] x=256, clamp is 255 min(255,256)
// limits=[0,255] x=-1, clamp is 0 max(-1,0)
// limits=[0,255] x=10, clamp is 10 max(0,10)
// 0 <= x <= 255
clamp = (a,b) => x => Math.min(Math.max(x,a), b)Clip
Normalization
You would only normalize it in order to display it, not in order compute with it.
Signal Processing
We use 1D discrete signals, that is, an array of numbers to represent gray images. A histogram of a gray-tone image is an array of bins, one for each gray tone.
Think image as tensor
An image is a tensor rank two.
Introduction
CV Process
- Process data from pixels.
- Obtain information from spatial correlations.
- Intrerpret images.
Common Tasks
- Classification: assign a label to image.
- Detection and localization: is there certain object? where? You might reduce this problem into classification.
- Segmentation: partition an image into regions (an object of interest). You might reduce this problem into classification.
- Generation: produce synthetic images
Applications
Style Transfer
Time Domain Description
Colorspaces
The Commission Internationale de l'Éclairage (CIE) is the organization responsible for maintaining standards related to light and color.
https://courses.cs.washington.edu/courses/cse576/23sp/notes/2_Color_Texture_FIN_20.pdf
https://www.youtube.com/watch?v=LFXN9PiOGtY
Transformations
Linear operations. Let and be vector spaces over a field An operator is linear if
for all in and for all in .
Shift invariant. Operator behaves the same everywhere.
Operations
Convolution
Convolution is a linear, shift invariant operator that is commutative and associative. Its identity is the unity impulse. Its differentation is .
https://betterexplained.com/articles/intuitive-convolution/
Morphology
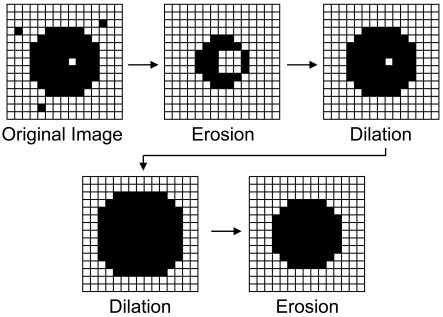
Sensors
RGB
LIDAR
NIR
SAR
Thermal
RG-DSM
Worked example
Low-level
High-level
We’re going to use Python, OpenCV, and Pillow.
Image processing
Kernels and filtering
Template matching
Model fitting and optimization
Deep learning
CNN
Tensorflow, Keras
Callbacks
Metrics
Pooling.
GPU
U-NET
Data augmentation
Pretrained Convolutional Neural Network models
Examples of CNN are ResNet, Inception,Xception, MobileNet, VGG16.
There are two ways to use pretrained CNN are fine-tuning and total transference.
CNN Boilerplate
Worked examples
MNIST handwritten digit database
Dogs and Cats
- Preprocessing
Captcha Solver
We classify Captcha in Normal Captcha, Text Captcha, reCaptcha 2, reCaptcha3,
CAPTCHAs often use a mix of tactics to prevent automated decoding, such as:
- Distorted text: The text in the CAPTCHA image is often distorted in some way to make it harder for software to recognize the characters. The letters might be skewed, rotated, or stretched, for instance.
- Background noise: CAPTCHAs frequently include background patterns, colors, or images to make it harder for software to separate the text from the background.
- Overlapping characters: The characters in the CAPTCHA text are often placed close together or even overlapping, which can confuse OCR software.
- Varied fonts and colors: CAPTCHAs often use a variety of different fonts, sizes, and colors, which can make it more difficult for software to recognize the characters.
- Line interference: Lines or shapes might be drawn over or through the text to confuse OCR software.
Object follower
https://towardsdatascience.com/automatic-vision-object-tracking-347af1cc8a3b
Representation learning
FAQ
How can I find out the best architecture?
Can I add new data during the training?
Are there available tools to label automatically?
https://github.com/abreheret/PixelAnnotationTool
Recognition
OCR
TrOCR
Feature detection and matching
Harris Corner Detector
OBS
SIFT
SURF
BRISK
AZAKE
Procrustes analysis and Wahba's problem
https://github.com/theochem/procrustes
Siamase neuronal network
Image aligment and stitching
Motion estimation
Computational photography
Structure from motion and SLAM
Depth estimation
3D reconstruction
Image-based rendering
Digital Image Processing
Digital images processing are everywhere in the today technician endevour. But what is a image? The images are the result of electromagnetic energy spectrum, acoustic, ultrasonic, and electronic whether we can see them or not. For that, some applications are X-Ray imaging, angiography, imaging in the ultraviolet band, imaging the visible and infrared bands, remote sensing.
Ecosystem
OpenCV is the major library for digital image processing.
Notes
Worked examples
FAQ
Further resources
Digital Image Processing, 4Th Edition by Rafael C. Gonzalez
https://www.youtube.com/watch?v=qByYk6JggQU&ab_channel=FirstPrinciplesofComputerVision
https://github.com/vinta/awesome-python
Case studies (projects)
If you wish to create a computer vision project, it normally requires a pipeline to successfully process your images or videos. Even if you don't need to use machine learning techniques, you must have a testing process.
Document Text Recognition
When your users interact with your systems through documents and lack access to a barcode format or more structured data (like computer-generated PDFs or web forms), your systems must possess some form of recognition capability over images. This project provides a pipeline to transform an image with free-text structure into a structured and meaningful data format like JSON.
The pipeline is as follows:
flowchart TB
subgraph predict
CaptureImage["Image"] --> ImageThresholding
subgraph denoise
ImageThresholding
-->SmoothingImage
-->MorphologicalTransformation
-->d...["..."]
--> feature-invariant
end
subgraph feature-invariant
SIFT
CNN
SiameseNeuralNetwork["Siamese neural network"]
Procustes
ORB
end
feature-invariant
--> TextDetection
--> TextRecognition
--> SemanticJSON
end
Medical Image Analysis
Bankman, I. (Ed.). (2008). Handbook of medical image processing and analysis. Elsevier.
Shen, D., Wu, G., & Suk, H. I. (2017). Deep learning in medical image analysis. Annual review of biomedical engineering, 19, 221-248.
References
Didactic Introductions
Richard Szeliski. “Computer Vision: Algorithms and Applications”. 2nd Ed. Springer Nature. 2022.
Rafael C. Gonzalez, Richard E. Woods. “Digital Image Processing”. 4th Ed. Pearson. 2018.
Roy Davies. “Computer Vision: Principles, Algorithms, Applications, Learning”. 5th Ed. Academic Press. 2017
Computer Vision, Linda G. Shapiro and George Stockman, Prentice-Hall, 2001.
Computer Vision: Algorithms and Applications, Rick Szeliski, 2010.
Rick's Second Edition, From Spring 2020.
Theory
Ian Goodfellow, Yoshua Bengio, Aaron Courville. “Deep Learning”. MIT Press. 2016
Simon J.D. Prince. “Understanding Deep Leanring”. MIT Press. 2023.
Francois Chollet. “Deep Learning with Python”. 2nd Ed. Manning. 2021.
Application
OpenCV3-Computer-Vision-with-Python-Cookbook
Courses
https://www.udacity.com/course/computer-vision-nanodegree--nd891
CSCI 1430: Introduction to Computer Vision. (2022, April 19). Retrieved from https://cs.brown.edu/courses/csci1430/2022_Spring/index.html
16-385 Computer Vision, Spring 2020. (2022, November 24). Retrieved from https://www.cs.cmu.edu/~16385
https://courses.cs.washington.edu/courses/cse576/
References
- Berry, R., & Burnell, J. (2000). Astronomical Image Processing. Willmann-Bell, Inc. [Clásica].
- Gonzalez, R. & Woods, R. (2018). Digital Image Processing (4th ed.). Pearson.
- Russ, J. & Neal, F. (2017). The Image Processing Handbook (7th ed.). CRC Press, Taylor & Francis Group. Available at: EBSCOhost.
- Shih, F. (2010). Image Processing and Pattern Recognition: Fundamentals and Techniques. John Wiley & Sons. [Clásica].
- Starck, J. & Murtagh, F. (2006). Astronomical Image and Data Analysis. Springer. [Clásica].
- Burger, W. & Burge, M. J. (2016). Digital Image Processing: An Algorithmic Introduction Using Java (2nd ed.). Available at: EBSCOhost [Clásica].
- ESA/NASA Hubble. A Short Introduction to Astronomical Image Processing. Available at: ESA Hubble.
- Milone, E., & Sterken, C. (2011). Astronomical Photometry: Past, Present, and Future. Springer New York. Available at: EBSCOhost [Clásica].
- OpenCV. (2021). OpenCV Tutorials. Available at: OpenCV Documentation.
https://www.youtube.com/watch?v=_NiKKCTpd2g
https://www.youtube.com/watch?v=tFSHT1dDgic
https://www.youtube.com/watch?v=l-GovgpV93w
https://www.youtube.com/watch?v=Rh6pKTNMjKY
https://www.youtube.com/watch?v=G4nFveLyzJo
https://www.youtube.com/watch?v=VsFEIBUe__I
https://www.youtube.com/watch?v=kR12pt-ipr4
https://www.youtube.com/watch?v=Pd17V_cNgz4
https://www.kaggle.com/datasets/mateocanosolis/hagdavs?datasetId=3451891
Repo Camilo Laiton:
https://github.com/camilolaiton/SelfAttention3DBrainSegmentation
Notebook tensorflow data augmentation:
https://www.tensorflow.org/tutorials/images/data_augmentation?hl=es-419
Albumentations:
https://github.com/albumentations-team/albumentations
https://drive.google.com/drive/folders/1NsfQrFMKe3MR-3_DLtAqRZM3yaLuWce7?usp=sharing
Next steps
TODO
Top 5 Object Tracking Methods
Assigments