
[Programa Delfín 2023] Asignación de CIE-10 a notas médicas en Español

Autores
Jacqueline Sámano Martínez , Universidad Mexiquense del Bicentenario
Gallego Rojo Laura Sophia, Universitaria Agustiniana Uniagustiniana, Colombia
Sequeda Castillo Kevin, Universidad de Investigación y Desarrollo, Colombia
José Ángel González Fraga, UABC
Carlos Eduardo Sánchez Torres, UABC
Resumen
Utilizando técnicas de procesamiento del lenguaje natural, Tensorflow y las API provistas por OpenIA, asignaremos los códigos CIE-10 (Clasificación Internacional de Enfermedades versión 10) a las interpretaciones que los médicos escriben en el sistema de información hospitalario cuando atienden a un paciente. Tradicionalmente, este es un proceso que se realiza manualmente y puede ser tanto laborioso como susceptible de errores. Este clasificador no solo ahorraría tiempo al personal médico, sino que también mejoraría la gestión de los datos de salud, facilitando análisis epidemiológicos y estudios de salud poblacional. Aunque el proyecto presenta desafíos significativos, como la complejidad y especificidad de la jerga médica y las consideraciones de privacidad de los datos, se espera que la implementación exitosa de este clasificador tenga un impacto considerable en la administración sanitaria.
Introducción
Problemática
TODO: Redactar una introducción. ¿Quién necesita la información? ¿Por qué? ¿Qué proponemos?
Desde su inicio la CIE ha sido de apoyo en los centros hospitalarios en distintos países, para la elaboración de estadísticas de morbilidad y mortalidad. Haciendo posible la obtención de información precisa sobre las enfermedades existentes y anteriormente identificadas, con el fin de conocer, evaluar e identificar enfermedades y contrarrestar posibles epidemias. Sin embargo, durante la aplicación de la CIE-10 (Clasificación Estadística Internacional de Enfermedades, Décima Revisión) en función de la asignación de codificadores para los diagnósticos médicos resultan laboriosos y expuesto a errores debido a la complejidad de codificación, ya que este proceso es realizado de manera tradicional, es decir, manualmente. De tal manera que, durante el proceso de evaluación médica en los sistemas hospitalarios conllevan retrasos, a fin de tomar mejores consultas en términos diagnósticos. Por consecuencia, se propone el desarrollo de un clasificador mediante la utilización de técnicas de procesamiento del lenguaje natural, Tensorflow y las API provistas por OpenIA, que mejore la gestión de los datos de salud, facilitando análisis epidemiológicos y estudios de salud poblacional. Esto con fin de ahorrar tiempo al personal médico en la elaboración y documentación precisa y con mayor calidad asistencial, monitorizar condiciones de salud pública y el establecimiento de políticas sanitarias.
Trabajos relacionados
Perotte et al. (2014) titulado "Diagnosis Code Assignment: Models and Evaluation Metrics". En este estudio, los investigadores construyeron modelos de clasificación para asignar automáticamente los códigos de diagnóstico ICD-9, un predecesor de la CIE-10, a las notas de alta médica. Utilizaron principalmente SVM con distintas variantes con métricas «F-measure», «precision» y «recall» 27.6%, 86.7% y 16.4% respectivamente (SVM plano).
Otro estudio relevante es el de Kavuluru et al. (2015) "An empirical evaluation of supervised learning approaches in assigning diagnosis codes to electronic medical records". Este estudio examinó la aplicación de la similitud semántica y el aprendizaje automático para mejorar la precisión de la codificación de diagnósticos.
El proyecto cTAKES (Clinical Text Analysis and Knowledge Extraction System) mantenido por la APACHE Software Foundation es un ejemplo relevante en el ámbito de la extracción de información de las notas médicas. cTAKES es una herramienta de código abierto que utiliza técnicas de NLP para extraer información clínica relevante de las notas médicas en inglés.
Cada uno de estos trabajos proporciona información y enfoques valiosos que pueden darnos inspiración para desarrollar nuestro clasificador de notas médicas de acuerdo a la CIE-10.
Metodología
TODO: Este es un proyecto de minería de datos con enfásis en procesamiento del lenguaje natural y sistemas de salud. Describe el flujo de trabajo con el marco de trabajo crisp-dm.

Descripción del conjunto de datos
TODO: Convertir esta brevísima descripción en algo con mayor color y detalles: texto descriptivo. ¿Qué es el CIE? ¿Cuándo nació? ¿Qué usan los médicos para encontrar el CIE? ¿Usan alguna aplicación? ¿Cómo los médicos determinan la interpretación? ¿Qué es una conclusión compatible?
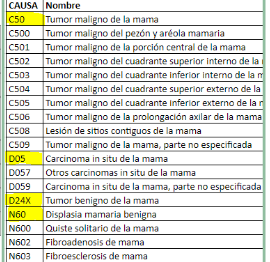
Interpretación. Texto abierto con las observaciones de los estudios y conclusiones compatibles por parte de un médico especialista.
CIE. Código de Clasificación Internacional de Enfermedades versión 10, que sigue la forma Capítulo Categoría Grupo Subcategoría.
Análisis exploratorio
TODO: Como este es un proyecto de NLP, el objetivo es mostrar gráficos representativos que incluye la frecuencia de palabras (removiendo stopwords), longitudes del texto (total de caracteres, oraciones, párrafos), análisis de n-gramas y medidas de legibilidad (Flesch-Kincaid, Gunning Fog y Dale-Chall.) así como comentarios o interpretaciones interesantes sobre los gráficos.
Algoritmos de aprendizaje
TODO: Probar distintas alternativas tales como los embeedings de OpenIA, LangChain, públicos y entrenar los propios con TensorFlow para clasificar las interpretaciones. ¿Qué es un embeeding? ¿Cómo funciona la API de OpenIA? ¿Cómo es posible conectar ChatGPT a Internet gracias LangChain y dar mejores resultados? ¿Es posible usar embeedings open source?
What are embeddings?: https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
Semantic text search using embeddings: https://github.com/openai/openai-cookbook/blob/main/examples/Semantic_text_search_using_embeddings.ipynb
Classification using embeddings: https://github.com/openai/openai-cookbook/blob/main/examples/Classification_using_embeddings.ipynb
Clasificadores: https://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
Resultados
TODO: Calcular y Mostrar las métricas. Compararse con los trabajos relacionados.
Conclusiones y trabajo futuro
TODO: Hablar si se logro el objetivo, limitaciones y trabajo futuro
Referencias
Practical Natural Language Processing by Sowmya Vajjala, Bodhisattwa Majumder, Anuj Gupta, Harshit Surana
https://eciemaps.mscbs.gob.es/ecieMaps/browser/index_10_mc.html
https://ais.paho.org/classifications/chapters/pdf/volume1.pdf
https://www.minsalud.gov.co/sites/rid/Lists/BibliotecaDigital/RIDE/IA/SSA/cie10-cie11.pdf
http://www.dgis.salud.gob.mx/contenidos/intercambio/diagnostico_gobmx.html
http://gobi.salud.gob.mx/gobi/descargas/manuales/Manual_Carga_Masiva_20220126.pdf?v=2022.06.01
https://www.youtube.com/playlist?list=PL5uSCzf1azhA0crlSVCYMPqMUWd4mXc4x
https://www.mdpi.com/2076-3417/10/15/5262
https://temu.bsc.es/codiesp/index.php/2019/09/19/datasets/
https://drive.google.com/drive/folders/1fdSWpTTfxOS2PwXQNFggUjd_2SliiVXU
https://colab.research.google.com/drive/1NfIylTcKDNyPtXHWtkJrz6m6IIziJvzB
https://arxiv.org/abs/2304.10513
https://www.pinecone.io/learn/series/langchain/langchain-intro/
Anexo
Plan de trabajo
Objetivos
- Crear un modelo de aprendizaje con un “accuracy” mayor o igual al 80%.
- Realizar un análisis exploratorio de los datos. Usar Python, Google Colab (privado).
- Utilizar los embeddings de OpenIA y calcular la distancia entre la interpretación y el CIE. Aunque el servicio actualmente es de paga, nosotros le proporcionaremos la API Key a los servicios de OpenIA.
- Buscar embeddings gratuitos y realizar lo mismo que el inciso b.
- Crear un modelo con Tensorflow.
- Evaluar y proponer alternativas.
Puntos extras: Despliegue del modelo.
- Crear una API REST que consuma el modelo en local. No está permitido subir el modelo a la nube.
- Usar FastAPI y CloudFlare.
- La API REST debe recibir una interpretación y debe devolver el CIE correspondiente.
- Crear una interfaz gráfica que consuma dicha API REST.
- Usar Gradio o EvaNotebook.
- El médico ingresa su interpretación y el sistema muestra en un «select» el CIE el cual puede ser modificado por el usuario.
Punto extra:
- Generar texto recomendado en tiempo real de la nota médica.
Datasets
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3932472/
Nosotros le proporcionaremos un dataset con las características «interpretación« y una variable objetivo «CIE».
https://zenodo.org/record/3837305#.XsZFoXUzZpg
https://temu.bsc.es/codiesp/index.php/2019/09/19/datasets/
https://www.mdpi.com/2076-3417/10/15/5262
https://www.mdpi.com/2076-3417/10/15/5262
https://physionet.org/content/mimiciii/1.4/